Note
Click here to download the full example code
Reading Well Data into Subsurface¶
Authors: Miguel de la Varga and Alexander Juestel
# This example will get into detail about how we are using `welly` and `striplog` to
# import borehole data.
# We start by using pooch to download the dataset into a temp file;
import pooch
from dataclasses import asdict
import matplotlib.pyplot as plt
from striplog import Component
import subsurface as sb
from subsurface.reader import ReaderFilesHelper
from subsurface.reader.wells import read_collar, read_survey, read_lith, WellyToSubsurfaceHelper, welly_to_subsurface
from subsurface.structs.base_structures.common_data_utils import to_netcdf
base_url = "https://raw.githubusercontent.com/softwareunderground/subsurface/main/tests/data/borehole/"
data_hash = "55d58e1e1ed22509579d46f736fa5f07f4428c6744bd16dbd919242d14348da7"
raw_borehole_data_csv = pooch.retrieve(url=base_url + 'kim_ready.csv',
known_hash=data_hash)
This dataset consist on a csv file containing the following columns: x, y, name, num, z, year, 7,8,9, altitude, base, formation, top, _top_abs and md. This is a good example of how varied borehole data can be provided. We will need to be able to extract specific information to construct the subsurface object.
# To read csv we are using `pandas` but since `pandas.read_csv` has a lot of arguments, we have created some
# helper classes to facilitate the reading of the data for this specific context. These *Helpers* are just a python
# data class with a bit of funcitonality for setter and getter.
# Also since well data sometimes is given in multiple files - for collars, asseys and surveys - we will read those
# subset of the data into its own `pandas.Dataframe`. Let's start:
reading_collars = ReaderFilesHelper(
file_or_buffer=raw_borehole_data_csv, # Path to file
index_col="name", # Column used as index
usecols=['x', 'y', 'altitude', "name"] # Specific columns for collar
)
# We can see the fields from the class easily converting it to a dict
asdict(reading_collars)
Out:
{'file_or_buffer': '/home/runner/.cache/pooch/7c2d6aa7551f31216f7236d3f9fb70a6-kim_ready.csv', 'usecols': ['x', 'y', 'altitude', 'name'], 'col_names': None, 'drop_cols': None, 'format': '.csv', 'index_map': None, 'columns_map': None, 'additional_reader_kwargs': {}, 'file_or_buffer_type': <class 'str'>, 'index_col': 'name', 'header': 'infer'}
The rest of fields of ReaderFilesHelper would be used for different .csv configurations. With a ReaderFilesHelper we can use it for specific functions to read the file into pandas:
We do the same for survey and lithologies:
Out:
/home/runner/work/subsurface/subsurface/subsurface/reader/wells/well_files_reader.py:140: UserWarning: inc and/or azi columns are not present in the file. The boreholes will be straight.
warnings.warn('inc and/or azi columns are not present in the file.'
At this point we have all the necessary data in pandas.Dataframe. However, to construct a subsurface.UnstructuredData object we are going to need to convert the data to the usual scheme of: vertex, cells, vertex_attr and cells_attr. To do this we will use welly and striplog
Welly is a family of classes to facilitate the loading, processing, and analysis of subsurface wells and well data, such as striplogs, formation tops, well log curves, and synthetic seismograms.
The class WellyToSubsurfaceHelper contains the methods to create a welly project and export it to a subsurface data class.
Out:
The following striplog failed being processed: []
In the field p is stored a welly project (https://github.com/agile-geoscience/welly/blob/master/tutorial/04_Project.ipynb) and we can use it to explore and visualize properties of each well.
wts.p
stripLog = wts.p[0].data['lith']
stripLog
Out:
Striplog(11 Intervals, start=0.0, stop=4604.7157137)
stripLog.plot()
plt.gcf()

Out:
<Figure size 150x1500 with 1 Axes>
Once we have the WellyToSubsurfaceHelper the function welly_to_subsurface will directly convert the objet to subsurface.UnstructuredData – using the trajectory module of welly.
formations = ["topo", "etchegoin", "macoma", "chanac", "mclure",
"santa_margarita", "fruitvale",
"round_mountain", "olcese", "freeman_jewett", "vedder", "eocene",
"cretaceous",
"basement", "null"]
unstruct = welly_to_subsurface(
wts,
table=[Component({'lith': l}) for l in formations] # This is to keep the lithology ids constant across all the wells
)
unstruct
Out:
The following boreholes failed being processed: []
<xarray.Dataset>
Dimensions: (points: 3350, XYZ: 3, cell: 3283, nodes: 2, cell_attr: 1, vertex_attr: 0)
Coordinates:
* points (points) int64 0 1 2 3 4 5 6 ... 3344 3345 3346 3347 3348 3349
* XYZ (XYZ) <U1 'X' 'Y' 'Z'
* cell_attr (cell_attr) object 'lith_log'
* vertex_attr (vertex_attr) int64
UWI (cell) object 'KerrXX' 'KerrXX' ... 'R.A._Shafter_A1'
Depth (cell) float64 40.56 121.7 202.8 ... 3.952e+03 4.035e+03
Dimensions without coordinates: cell, nodes
Data variables:
vertex (points, XYZ) float64 2.932e+05 3.924e+06 ... -3.963e+03
cells (cell, nodes) int64 0 1 1 2 2 3 ... 3347 3347 3348 3348 3349
cell_attrs (cell, cell_attr) int64 1 1 1 1 1 1 1 ... 14 14 14 14 14 14 14
vertex_attrs (points, vertex_attr) float64
We can save the data into a netcdf by simply calling
to_netcdf(unstruct, "wells_unstructured_temp.nc")
We are done. Now the well data is a subsurface.UnstructuredData and can be used as usual.
element = sb.LineSet(unstruct)
pyvista_mesh = sb.visualization.to_pyvista_line(element, radius=50)
# Plot default LITH
interactive_plot =sb.visualization.pv_plot([pyvista_mesh])
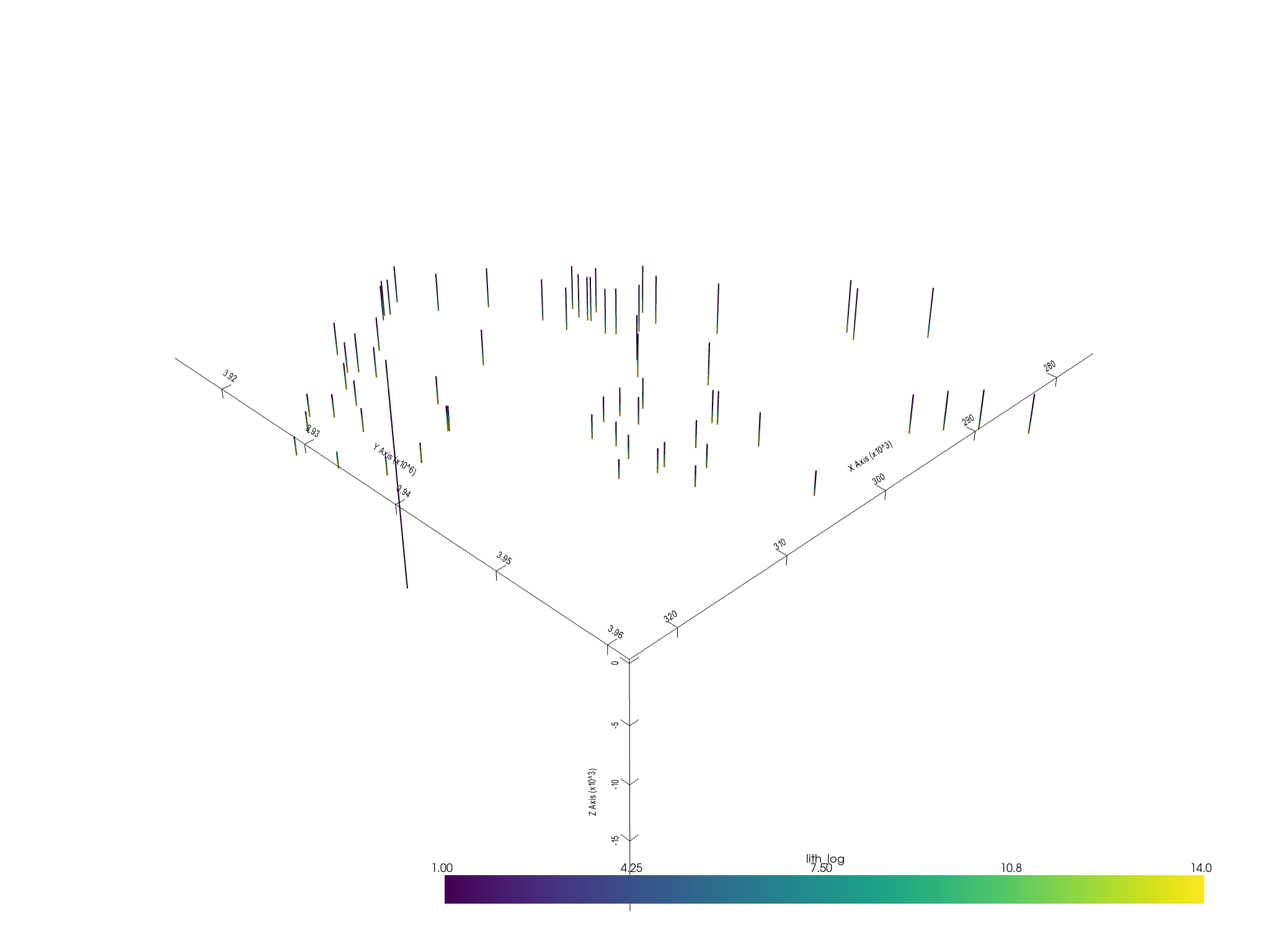
Out:
/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pyvista/core/dataset.py:1332: PyvistaDeprecationWarning: Use of `cell_arrays` is deprecated. Use `cell_data` instead.
warnings.warn(
Total running time of the script: ( 0 minutes 2.263 seconds)